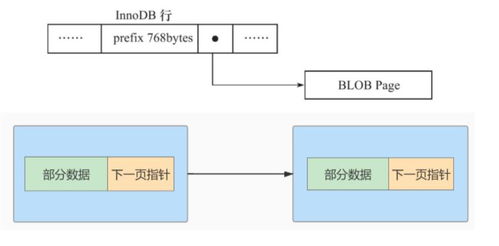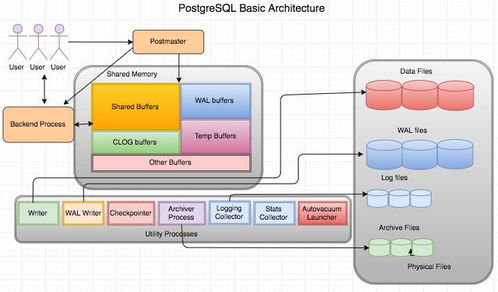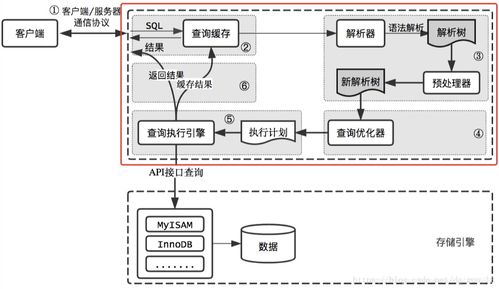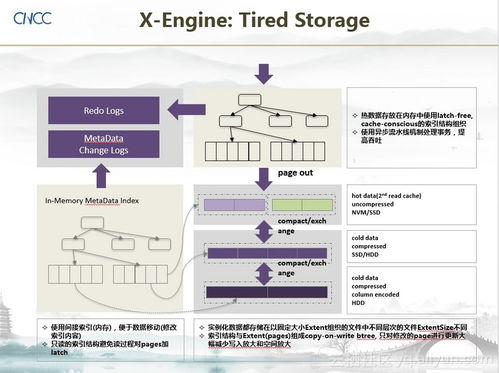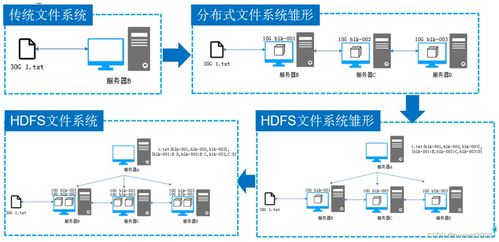
Hadoop分布式文件系统(HDFS)是Apache Hadoop生态系统的核心组件之一,专为处理大规模数据集而设计。它提供了一个高度可靠、可扩展且容错的存储解决方案,是支撑现代大数据处理与分析的基础设施。
一、HDFS的基本架构
HDFS遵循主从(Master-Slave)架构,主要由两个核心组件构成:
- NameNode(主节点):作为HDFS的“大脑”,负责管理文件系统的元数据(如文件名、目录结构、文件块位置等)。它维护着整个文件系统的命名空间,并协调客户端对文件的访问。
- DataNode(从节点):负责实际的数据存储。文件被分割成固定大小的数据块(默认为128MB),并分布式地存储在多个DataNode上。DataNode定期向NameNode报告其存储状态,确保数据的完整性和可用性。
HDFS还包含Secondary NameNode(辅助节点),它并非NameNode的实时备份,而是定期合并编辑日志与文件系统镜像,协助NameNode减轻元数据管理的负担。
二、HDFS的关键特性
- 高容错性:数据默认被复制为三个副本,存储在不同机架的DataNode上。即使某个节点或机架发生故障,数据仍可从其他副本恢复。
- 高吞吐量访问:HDFS优化了顺序读写操作,适合批处理任务(如MapReduce),而非低延迟的随机访问。
- 可扩展性:通过横向添加DataNode,HDFS可轻松扩展到数千个节点,支持PB级数据存储。
- 经济性:基于商用硬件构建,降低了存储成本。
三、HDFS在数据处理与存储中的角色
作为数据处理和存储的支持服务,HDFS在以下场景中发挥关键作用:
- 数据湖基础:企业常将HDFS作为数据湖的核心存储层,集中存储结构化、半结构化和非结构化数据,为后续的ETL、分析和机器学习提供统一数据源。
- 批处理支持:HDFS的高吞吐量与Hadoop MapReduce、Spark等批处理框架无缝集成,支持对海量数据进行离线分析。
- 数据冗余与备份:通过副本机制,HDFS确保了数据的持久性和可靠性,减少了因硬件故障导致的数据丢失风险。
- 流式数据处理:结合Kafka、Flume等工具,HDFS可作为流式数据的最终存储目的地,支持实时或近实时分析。
四、HDFS的局限性
尽管HDFS功能强大,但也存在一些限制:
- 不适合存储大量小文件,因为NameNode的元数据存储受内存限制。
- 不支持文件的随机修改,仅允许追加写入。
- 高可用性需通过NameNode的HA配置实现,增加了部署复杂度。
五、未来演进
随着云原生和对象存储(如AWS S3)的兴起,HDFS的部署模式也在变化。许多企业开始采用混合存储策略,将HDFS与云存储结合,以平衡性能、成本与弹性。HDFS自身也在持续优化,例如通过纠删码(Erasure Coding)替代副本机制以提升存储效率。
HDFS作为大数据时代的基石,通过分布式、容错的存储设计,为数据处理提供了坚实后盾。理解其基本概念与特性,有助于更有效地构建和维护大规模数据平台。